완전 Modern이라고 하기엔 어폐가 있으니 주의하며 강의를 듣자.
네트워크를 깊게 쌓아가면서 Parameter를 줄여나가는 기술을 알아가보자.
AlexNet
AlexNet은 2012년에 개최된 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge) 대회의 우승을 차지한 CNN 구조이다.

AlexNet이 잘 될 수 있었던 이유는 다음과 같다.
- Rectified Linear Unit(ReLU) activation : 활성 함수가 가져야 하는 큰 특징은 비선형(Non-Linear)이다. ReLU도 비선형 함수라고 볼 수 있다. 0보다 클 때에 기울기(slope)가 1이기 때문에 원하는 gradient가 사라지거나 레이어를 깊게 쌓았을 때 네트워크를 망칠 수 있는 성질들이 많이 없다.
- GPU implementation (2 GPUS)
- Local response normalization, Overlapping pooling : LRN은 어떤 입력 공간에서 response가 많이 나올 때 몇 개를 없애는 것이다. 최종적으로 원하는 건 sparse한 activation이 나오는 것이지만 현재는 많이 쓰이지 않는다.
- Data augmentation : 주어진 데이터에 변형을 가해서 레이블이 변하지 않는 조건 하에 데이터셋을 늘려가는 것
- Dropout : NW Weight를 0으로 바꾸는 것으로, 뉴런과 인퍼런스를 할 때 뉴런 50%를 0으로 바꿔주면 각각의 뉴런이 robust한 feature을 잡을 수 있다. 성능이 많이 올라가게 된다.
지금은 당연하지만 그 당시에는 그러지 않았기에 딥러닝의 기준을 잡아준 예시라고 할 수 있다.
ReLU Activation
- 선형 모델이 갖고 있는 좋은 성질을 가지고 있다.(Preserves properties of linear models)
- 경사하강법으로 최적화하기 용이하다.(Easy to optimize with gradient descent)
- Good generalization
- Overcome the vanishing gradient problem : sigmoid나 tanh의 경우 0을 기점으로 값이 커지면 slope가 점점 줄어든다. 가지고 있는 뉴런의 값이 많이 벗어나면 그곳에서 나오는 slope는 0에 가깝게 된다. ReLU는 이런 문제를 해결한다.
VGGNet
VGGNet은 2014년에 개최된 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge) 대회의 준우승을 차지한 CNN 구조이다.

가장 큰 특징은 3 × 3 Convolution filter를 사용한 점이다. Convolution filter의 크기가 커짐으로써 가지는 이점은 하나의 필터가 찍었을 때 고려되는 input의 크기가 커진다. 이게 소위 말하는 Receptive field다. 하나의 Convolution feature map 값을 얻기 위해 고려할 수 있는 입력의 special dimension을 말한다.
3 × 3 을 두 번 실행한 convolution은 input 레이어의 3 × 3, 다음으로 intermediate 레이어의 3 × 3 하여 output을 낸 것이다. 그런데 그냥 input 레이어에서 5 × 5 convolution 한 번해서 output을 낸 것도 receptive field 측면에서는 같다. 게다가 파라미터 수는 3 × 3 을 두 번 사용한 경우가 더 적다. 이래서 추후 논문들을 보면 웬만해서는 3 × 3, 5 × 5 필터를 사용하는 것이 이 이유다.

GoogLeNet
GoogLeNet은 2014년에 개최된 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge) 대회의 우승을 차지한 CNN 구조이다.

구조를 보면 1 × 1 Conv가 나타난다. 하나의 입력에 대해서 여러 개의 receptive field를 갖는 필터를 거치고, 여러 개의 response를 concatenate하는 효과도 있지만 결정적으로 파리미터의 개수를 줄여준다. 채널 방향으로 차원을 축소(Channel-wise dimension reduction)하는 효과가 있는 것이다.

ResNet
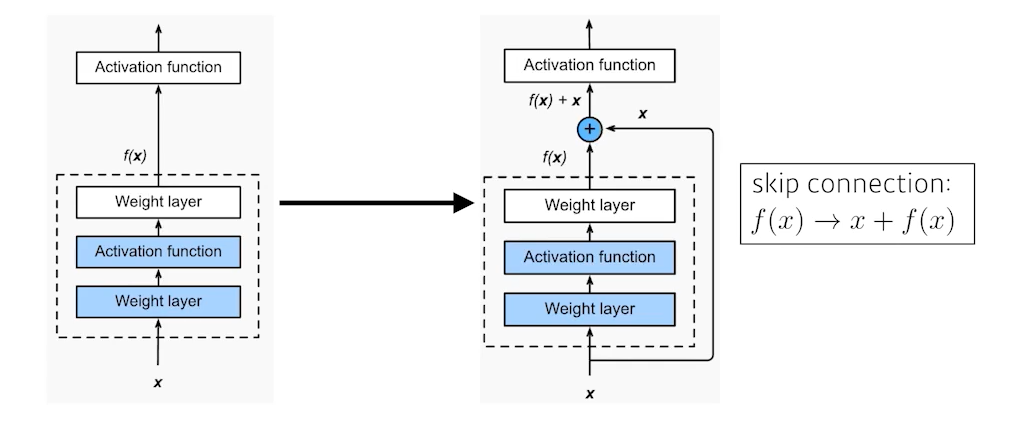
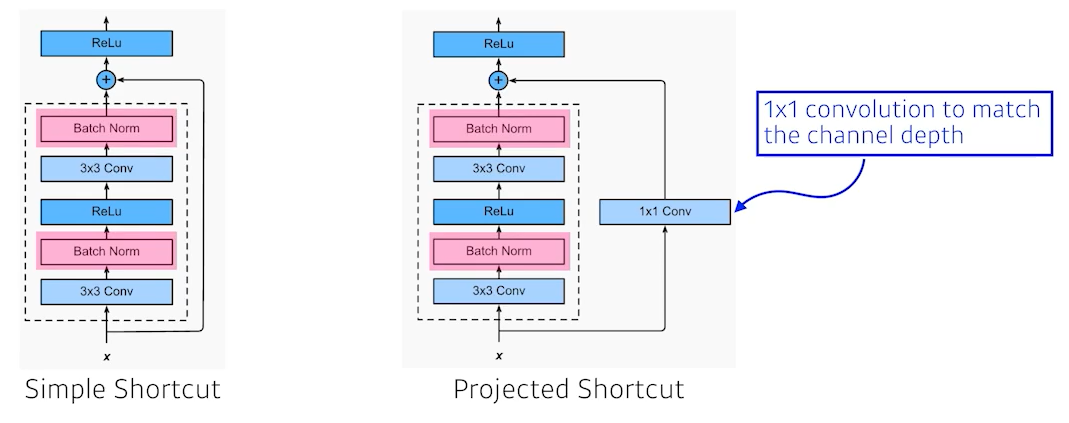
identity map을 추가했다. 기존의 신경망은 x를 y로 매핑하는 함수를 찾는 게 목표였으나, ResNet은 $f(x) + x$를 최소화하는 것을 목적으로 한다. x는 현시점에서 변할 수 없는 것이니 $f(x)$를 0에 가깝게 만드는 것이 목적이 된다. $f(x)$가 0이 되면 출력과 입력이 모두 x로 같아지게 된다. x를 뉴럴 네트워크의 출력값에 한 단짜리 convolution 레이어에 더해준다. 원하는건 convolution 레이어가 학습하고자 하는 값(quantity)은 차이(residual)만 학습하는 것이다. x에다가 f(x)를 더했으니 실제 f(x)가 학습하는 건 그 차이만 학습하길 원하는 것이다.
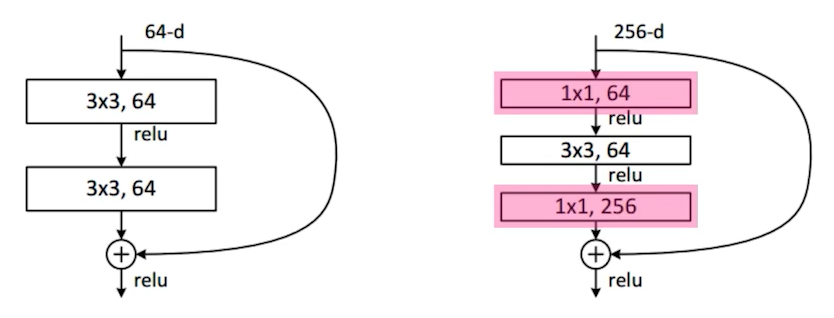
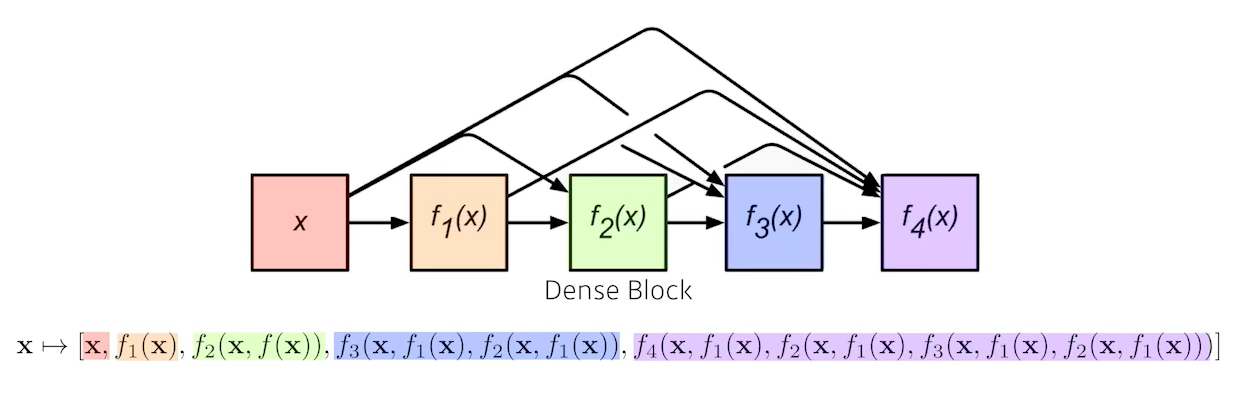
DenseNet
ResNet과 달리 더해주지(addition) 않고 concatenation 하는 것이다.
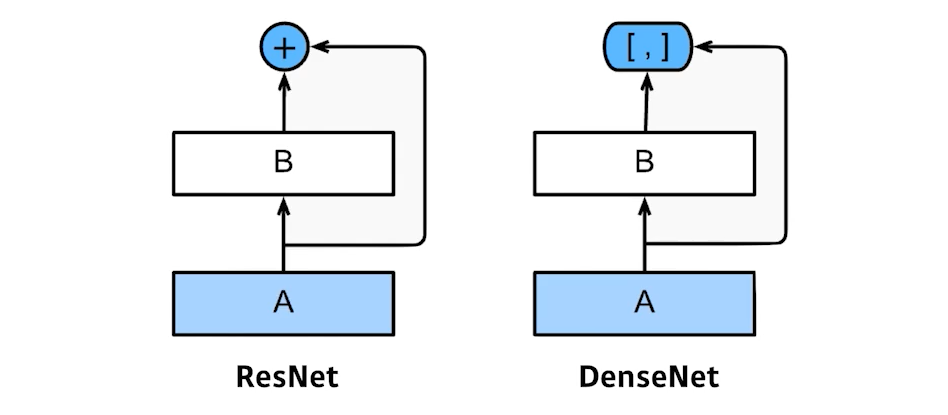
concatenation을 거치면 채널이 2배, 4배, 8배 … 와 같이 모든 채널을 더했기 때문에 기하급수적으로 커진다. 채널이 커지면 거기에 가해지는 convolution feature map의 채널(파라미터) 값도 커진다. 이럴 때는, 기하급수적으로 커진 채널(Dense Block)을 Transition Block(BatchNorm → 1 × 1 Conv → 2 × 2 Pooling)를 통해 파라미터 수를 줄인다. 늘리고 줄이는 과정을 반복하는 게 DenseNet이다.

'AI / DL > boostcourse' 카테고리의 다른 글
| [딥러닝 기초 다지기] 5. Generative Models (1) (0) | 2022.12.02 |
|---|---|
| [딥러닝 기초 다지기] 4-2. Sequential Models - Transformer (0) | 2022.11.02 |
| [딥러닝 기초 다지기] 3-3. Computer Vision Applications (0) | 2022.10.25 |
| [Github으로 따라하는 버전 관리] Git 협업 (0) | 2022.10.07 |
| [Github으로 따라하는 버전 관리] Git 기초 (0) | 2022.10.07 |




댓글