[주의!] 해당 강의는 매우 어려울 수 있습니다.
Transformer(Attention is All You Need, NIPS, 2017)
Transformer 구조는 기본적으로 Sequential 데이터를 다루는 방법론이다. Sequential한 데이터는 중간에 어떤 경로가 빠지거나, 순서가 뒤바뀌는(permutation) 일이 생기면 모델링하기 어렵다. 이런 일을 해결하기 위해 Transformer가 나타났다.
Transformer is the first sequence transduction model based entirely on attention.
RNN에서는 하나의 입력이 들어가고 다른 입력이 또 들어가고, 이 때 이전 Recurrent Neuron Network에서 가지고 있던 Cell State가 다시 다음 입력에 들어가며 반복적, 재귀적으로 돌아가는 구조였다. Transformer는 이런 재귀적인 구조가 없고, attention이라 불리우는 구조를 활용하여 시퀀스를 다루는 모델이다.
원래 이 논문이 처음 시도되었던 기계화 번역(NMT) 문제에 Transformer가 어떻게 적용되는지 설명한다. 첫 번째로 이 방법론은 Sequential 데이터를 처리하고 이 데이터를 Encoding하는 방법이기 때문에 NMT 문제에만 적용되지 않는다. Transformer 구조가 단순히 기계화 번역뿐만 아니라 이미지 분류, Image Detection, Visual Transformer 등에 적용된다. 최근 DALL·E라는 방법론은 문장이 주어지면 그에 맞는 이미지를 생성해준다. 정확히 Transformer 기반은 아니지만 그 내부에는 Self-attention이라는 Transformer에서 사용되는 원리가 적용된다.

어떤 문장이 주어지면, 다른 언어로 번역하는 문제는 Sequence to Sequence 모델이라 한다. 이 때 입력 시퀀스와 출력 시퀀스의 단어 수가 다를 수 있고, 서로의 도메인도 다를 수 있다. 한 가지 유추할 수 있는건 RNN은 세 개의 단어가 들어가면 세 번 네트워크가 돌아가는데, Transformer Encoder는 몇 개의 단어가 들어가든 그 단어의 수만큼 재귀적으로 돌아가지 않고 한 번에 인코딩할 수 있다. Generation할 때는 한 단어씩 하게 되더라도, Encoder (Self-attention) 구조에서는 n개의 단어를 한 번에 처리할 수 있다.
동일한 구조를 갖지만, 네트워크 파라미터가 다르게 학습되는 encoder와 decoder가 stack 되어 있다. 여기서 중요하게 봐야할 점은 세 가지 정도가 있다.
- n개의 단어가 어떻게 encoder에서 한 번에 처리가 되는가?
- encoder와 decoder 사이에 어떤 정보를 주고 받는가?
- decoder가 어떻게 generation을 하는가?
n개의 단어가 어떻게 encoder에서 한 번에 처리가 되는가?
encoder에 n개의 단어가 한 번에 들어간다. 그러면 Self-Attention이라는 구조와 Feed Forward Neural Network라는 구조를 한 단씩 거치는게 하나의 encoder고, 출력되서 나오는 n개의 출력값이 두 번째 레이어 encoder로 들어가며 반복된다.
The Self-Attention in both encoder and decoder is the cornerstone of Transformer.
FFNN은 사실상 MLP와 유사하고, Self-Attention이 주목할 만한 부분이다.

세 개의 단어가 들어간다 해보자. 기본적으로 기계가 번역할 수 있게 각 단어마다 특정 숫자의 벡터로 표현하게 된다. 따라서 주어진 건 세 개의 벡터다. 이 때 Self-Attention은 각 단어마다의 벡터를 찾아주는 역할을 한다. 중요한 점은 벡터에서 벡터로 가는게 하나의 FFNN라고 볼 수 있지만, 여기서 Self-Attention은 $x_1$이 $z_1$으로 넘어갈 때 단순히 $x_1$의 정보만 활용하는 게 아니라 $x_2$와 $x_3$의 정보를 같이 활용한다. 바꿔말하면 n개의 단어가 주어지고, n개의 z 벡터를 찾는데 각각의 i번째 x벡터를 $z_i$로 바꿀 때, 나머지 n-1개의 x 벡터를 같이 고려하는게 Self-Attention의 가장 큰 묘미라고 할 수 있다.

Self-Attention은 dependencies가 있다. n개의 단어를 만들 때 나머지를 활용하게 되고, FFNN은 dependency가 없다. 그저 z 벡터를 변환해주는 것에 불과하다.
Self-Attention at a high level
The animal didn't cross the street because it was too tired.
이런 문장이 있다. 이 문장을 이해할 때 중요한 점은 뒤에 나오는 it이 어떤 단어에 dependent 하는지 알아야한다. 바꿔말하면 하나의 문장에 있는 단어를 설명할 때 그 자체로만 이해하면 되는게 아니라 문장 속에서 다른 단어들과 어떤 관계가 있는지를 봐야한다.

Transformer는 it이라는 단어를 encoding할 때, 다른 단어들과의 관계성을 보게 되고, 특별히 학습된 결과를 보면 it이 animal과 굉장히 높은 관계가 있음을 알아서 학습한다. 이런 식으로 학습하여 더 단어를 잘 표현하고 기계가 이해할 수 있는 것이다.
Encoder 이해하기

기본적으로 Self-Attention 구조는 세 가지 벡터(NN)를 만든다. Query, key, Value 벡터다. 각 단어마다 세 개의 벡터를 만들게 되고 이 세 개의 벡터를 통해서 단어의 Embedding vector를 새로운 벡터로 바꿔줄 것이다.

예를 들어 $x_1$(Thinking)을 encoding하기 위해서 먼저 score 벡터를 만들어야 한다. score 벡터는 encoding하고자 하는 단어의 query 벡터와, 나머지 모든 n개 단어(자신 포함)에 대한 key 벡터를 구해서 두 개를 내적(inner product)한다. 이 과정의 의미는 i번째 단어가 나머지 단어와 얼마나 유사도가 있는지, 관계가 있는지를 정하는 것이다. encoding하고자 하는 벡터의 query 벡터와, 자기 자신을 포함한 나머지 벡터들의 key 벡터를 구해서 두 개의 내적을 한다.


내적을 한 게 i번째 단어와 나머지 단어들 사이에 얼마나 interaction 해야 하는지를 알아서 학습하게 하는 것이고, 특정 task를 수행할 때 어떤 입력들을 더 주의깊게 볼지 해당하는게 일반적인 attention에서 나오게 된다. 여기서는 thinking이라는 단어를 encoding 하고 싶은데 어떤 자기 자신 혹은 나머지 단어들과 더 많이 interaciton이 일어나야 되는지를 query 벡터와 나머지 벡터들의 key 벡터 사이의 내적으로 표현하는 것이다.

내적 하고 score 벡터가 나오면 normalization을 해준다. score 벡터를 $\sqrt{d_k}$로 나누는데 여기서 $d_k$는 Key 벡터의 dimension에 dependent한다. 정확히는 key 벡터는 hyper parameter이다. $d_k$의 square root를 취해서 나눠주어서 값 자체가 너무 커지지 않게 만들어주는 역할을 한다. 이후 Softmax를 취해서 attention weights를 구할 수 있다. 각각의 단어가 다른 단어와의 interaction 정도(scalar)이다.

중요한 것은 그 값이 어떤 값이 될 지를 value 벡터가 가져오게 된다. 최종적으로 직접 사용할 값은 각각의 단어에서 나오는 value 벡터들의 weighted sum이 된다. value 벡터들의 weight를 구하는 과정이 각 단어에서 나오는 query 벡터와 key 벡터 사이의 내적, normalize하고 softmax 취해주고 나오는 attention을 value 벡터와 weighted sum을 한게 최종적으로 나오는 thinking이라는 단어에 해당하는 embedding vector의 어떤 encoding된 벡터이다. 이렇게 말한 루틴을 거치면 하나의 단어에 대한 encoding 벡터가 나오게 된다.
주의할 점은 query 벡터와 key 벡터의 차원이 항상 같아야 한다. 내적해야 하기 때문이다. value 벡터는 weighted sum을 하기만 하면 되니 차원이 달라도 된다. 그리고 최종적으로 나오는 thinking이라는 벡터의 인코딩된 벡터의 차원은 value 벡터의 차원과 동일하다. 물론 multi-head(ed) attention에서는 달라진다.


Transformer는 왜 성능이 좋을까? 이미지 하나가 주어졌다고 생각해보자. 이미지 하나를 CNN나 MLP로 바꿀 때, input이고정되어 있으면 출력도 고정된다. 네트워크 내 operation 통해서 나오는 Convolution filter나 weight가 고정되어 있기 때문이다. 하지만 Transformer는 하나의 input이 고정되거나 네트워크가 fix 되어 있다 하더라도, encoding 할려는 단어와 그 옆에 있는 단어에 따라서 인코딩된 값이 달라진다. 즉, MLP보다 더 flexible한 모델인 것이다. 입력이 고정돼서 출력이 고정이 아니라 입력이 고정되더라도 옆에 주어진 다른 입력이 달라지면 출력이 달라질 여지가 있다. flexible 하기 때문에 훨씬 더 많은 것을 표현할 수 있다. 바꿔말하면 더 많은 것을 표현하기 때문에 더 많은 computation이 필요하다. 여기서 볼 수 있는 computation bottleneck은 n개의 단어가 주어지면 기본적으로 n × n 짜리 어떤 attetion map을 만들어야 한다. 한번에 처리하고자 하는 단어가 1000개면 1000 by 1000짜리 입력을 처리해야 하는 것이다. RNN은 1000개의 시퀀스가 주어지면 천 번 돌리면 된다. 돌릴 수만 있으면 처리할 수 있는 것이다. Transformer는 n개의 단어를 한번에 처리해야 하고 그 computational cost가 $n^2$에 비례하기 때문에, 길이가 길어짐에 따라 처리할 수 있는 한계가 있다. 메모리를 많이 먹기도 하지만, 덕분에 훨씬 더 flexible하고 많은 것을 표현할 수 있는 네트워크를 만들 수 있다.
Multi-headed Attention(MHA)
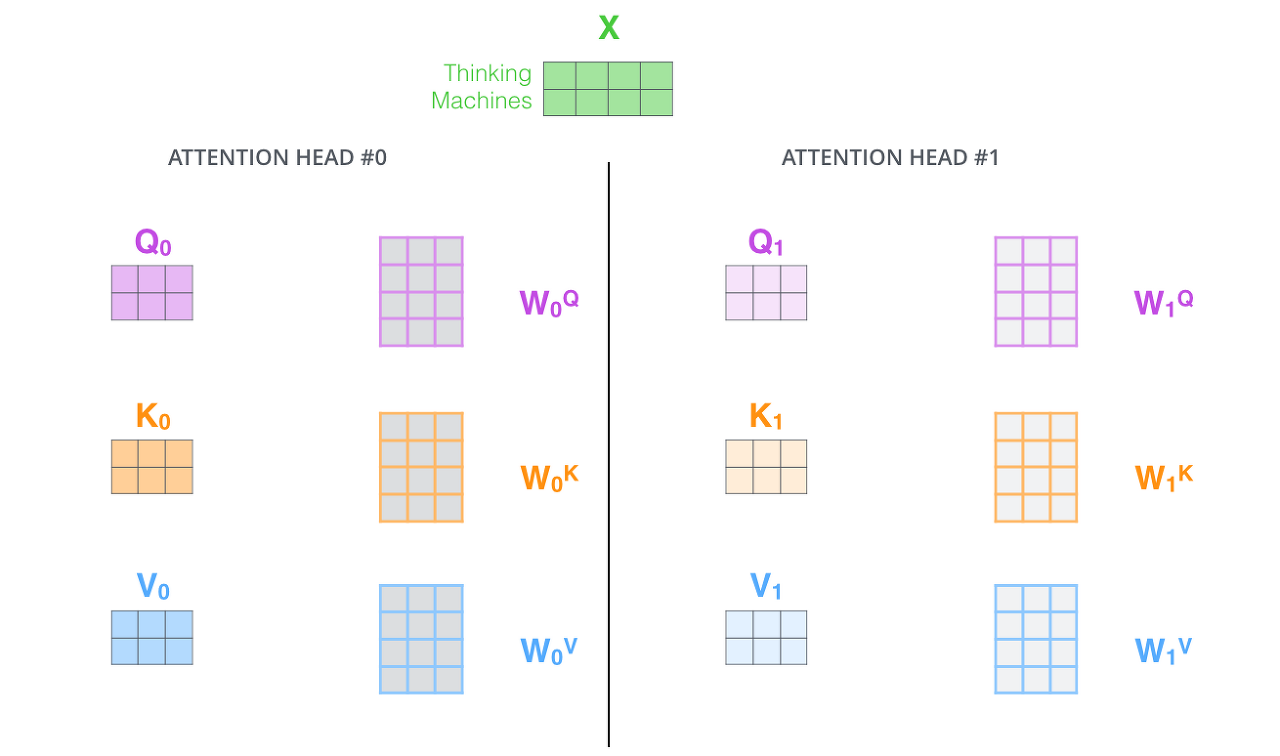
MHA은 앞에서 말한 Attention을 여러 번 하는 것이다. 하나의 encoding된 벡터에 대해서 query, key, value 벡터를 하나만 만드는게 아니라 n개 만드는 것이다. n개의 attention을 반복하게 되면 n개의 encoding된 벡터가 나오게 된다.


여기서 고려해야 할 점은 encoding 이후 다음 encoder로 넘어가야 하는데, 이 과정이 여러 번 stack되기 위해서 필요한 것은 입력과 출력의 차원을 맞춰줘야 한다. Embedding된 차원과 encoding 되어서 Self-attention으로 나오는 벡터가 항상 같은 차원이어야 한다. 예를 들어 8개의 head가 나왔고, 각 10 dimesnion이었으면 총 80 dimension짜리 encoding 벡터가 있으니 80 by 10 행렬을 곱해서 10차원으로 줄여버리는 방식으로 정보를 압축한다.
이 과정을 요약하자면 아래 그림과 같다.

Positional Encoding

입력에 특정값을 더해준다. Transformer 구조를 생각해보면 n개의 단어를 sequential하게 넣어줬다고 하지만, 사실 sequential한 정보는 이 안에 포함되어 있지 않다. 어떤 순서로 단어를 넣든 encoding되는 값은 달라질 수가 없다. Self-attention은 순서(order)에 독립적이다. 하지만 문장을 만들 때는 어떤 단어가 먼저 나오고 뒤에 나오는지가 중요하기 때문에 Positional encoding이 나타났다. 일종의 offset을 가하는 것.
encoder와 decoder 사이에 어떤 정보를 주고 받는가?

프랑스어 문장을 영어로 번역하는 문제를 보자.
encoder는 어떤 단어를 표현하는 거고, decoder는 그걸 갖고 무언가를 생성하는 것이었다. 그 사이에 어떤 정보가 전해지는지가 중요하다. Transformer는 결국 K와 V를 보낸다. 다시 말하자면 이 K와 V는 input word에서 나온 것이다. 이 K와 V는 각 decoder에서 문장의 적절한 위치를 찾도록 도와주는 "Encoder-Decoder Attention" 레이어에 사용될 것이다. input에 있는 단어와 decoder에서 출력하고자 단어들에 대해서 Attention map을 만들려면, input에 해당하는 단어들의 K, V가 필요하다. encoding이 끝나면 decoding이 시작된다. decoding의 각 단계는 출력 sequence로부터 요소를 출력한다. 최종 출력은 자기회귀적(autoregressive)이게, 하나씩 만들게 된다.
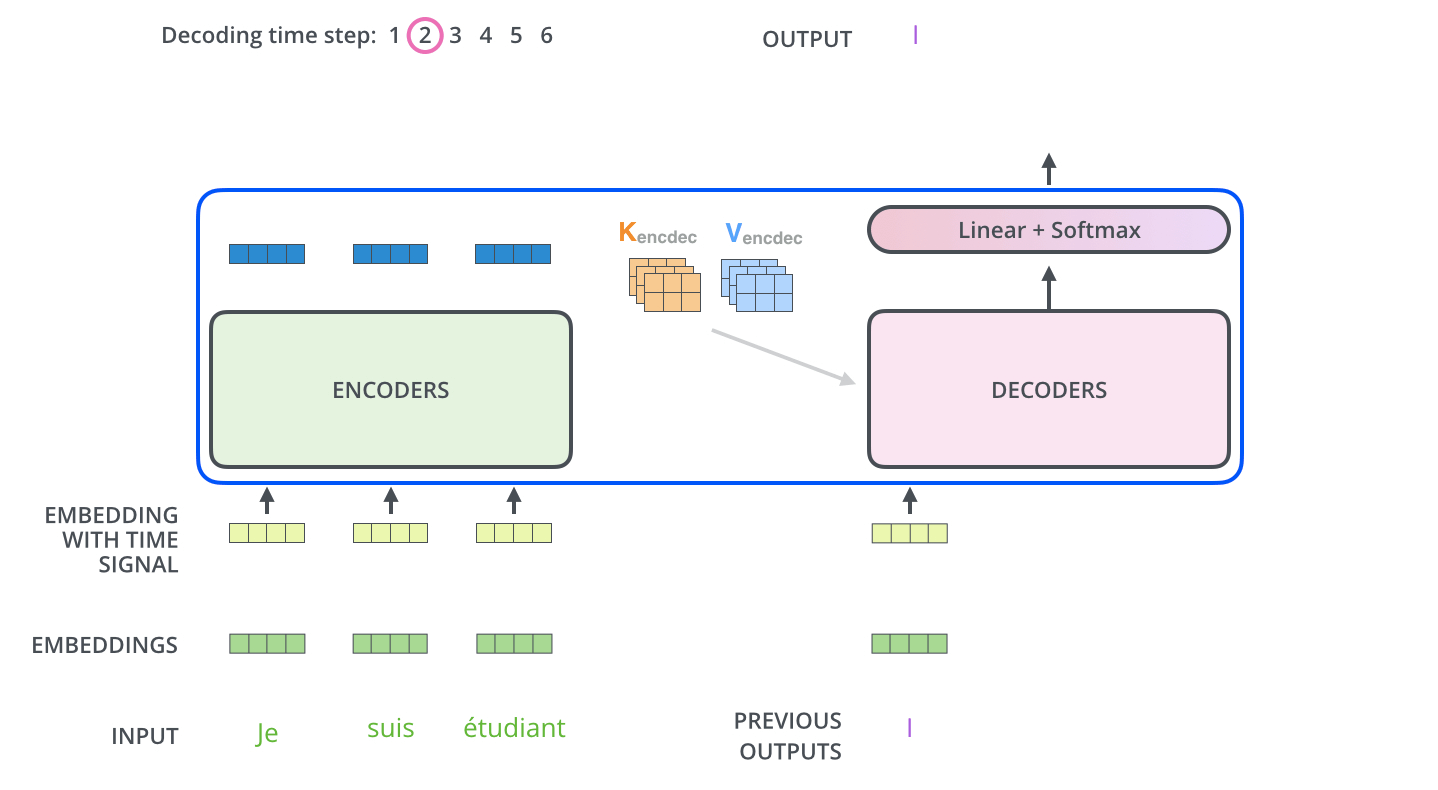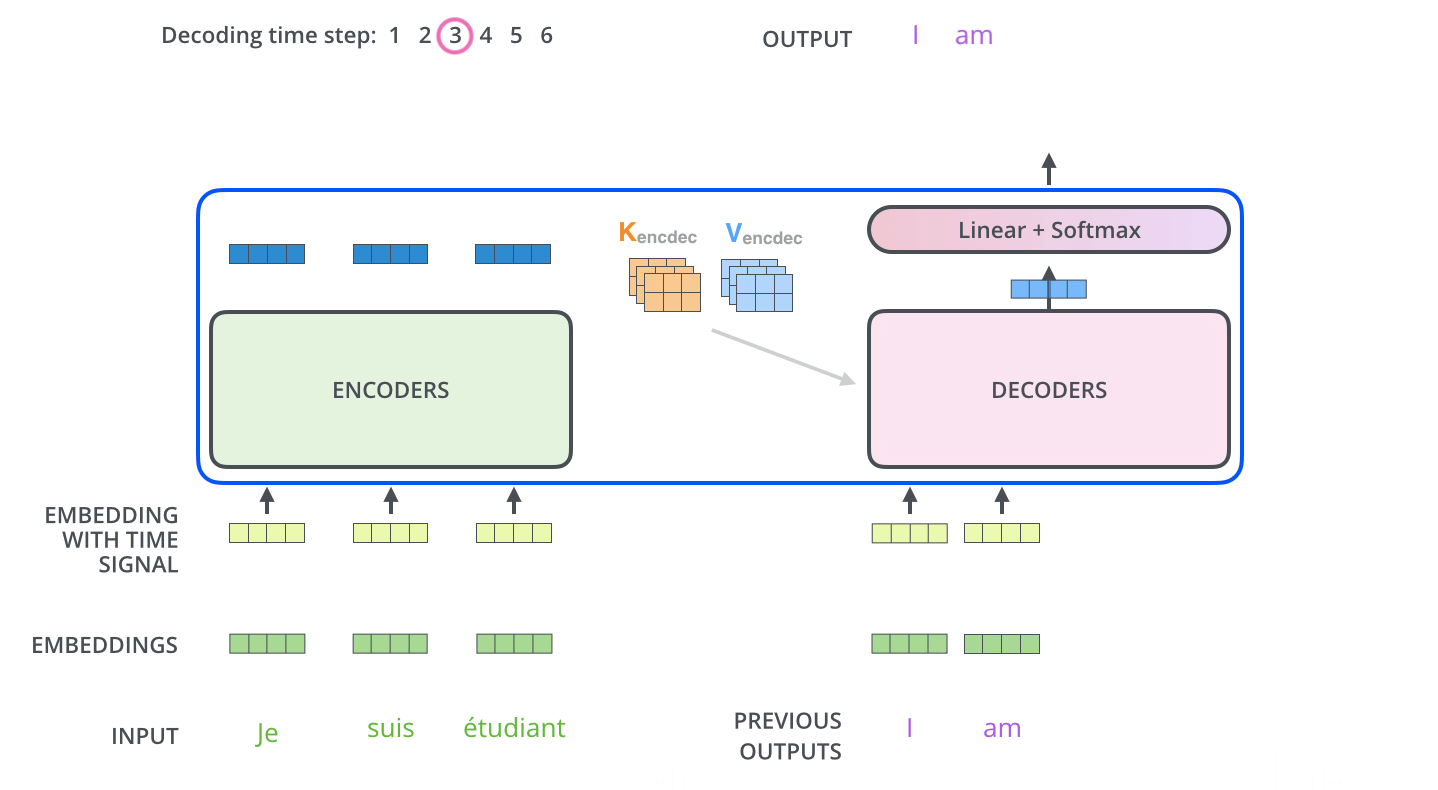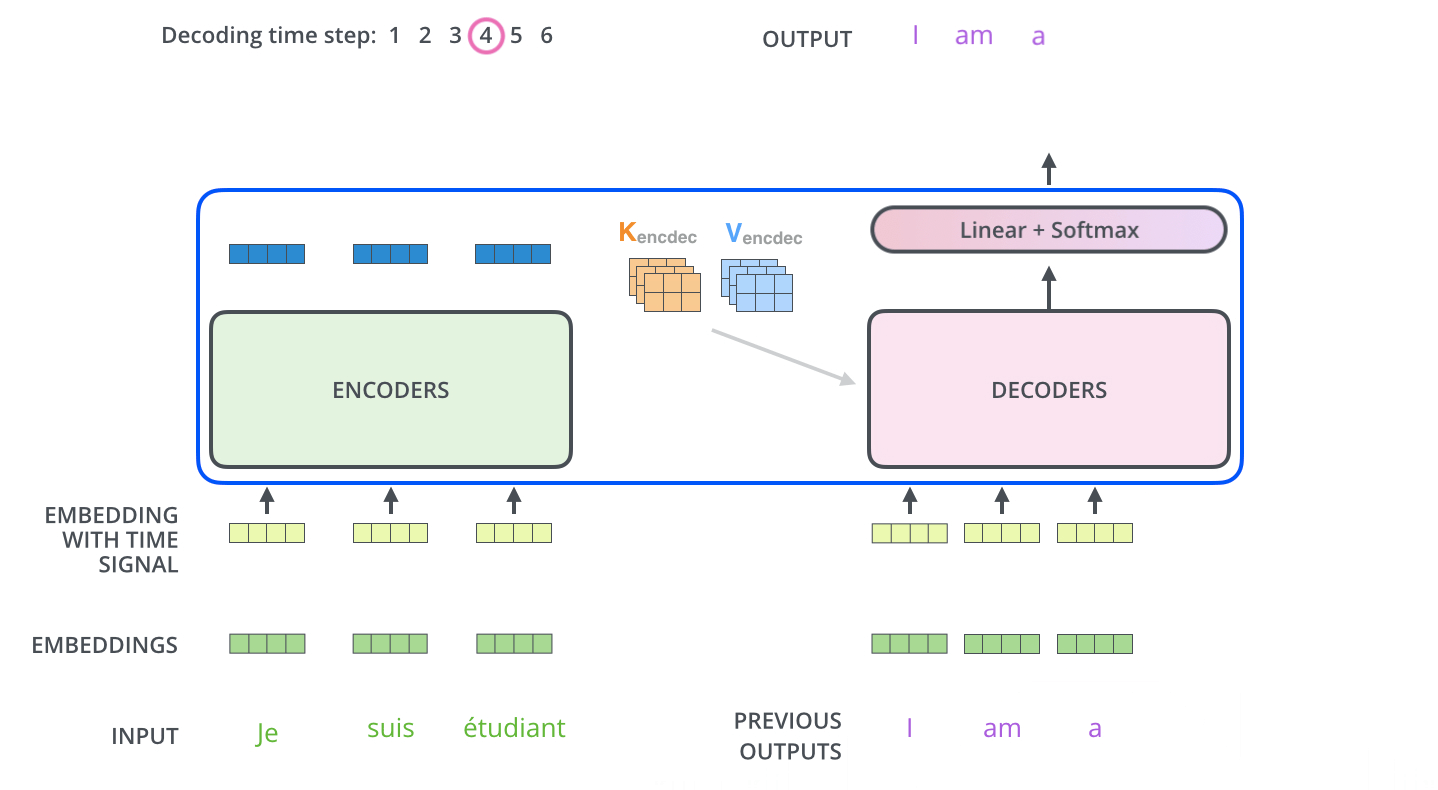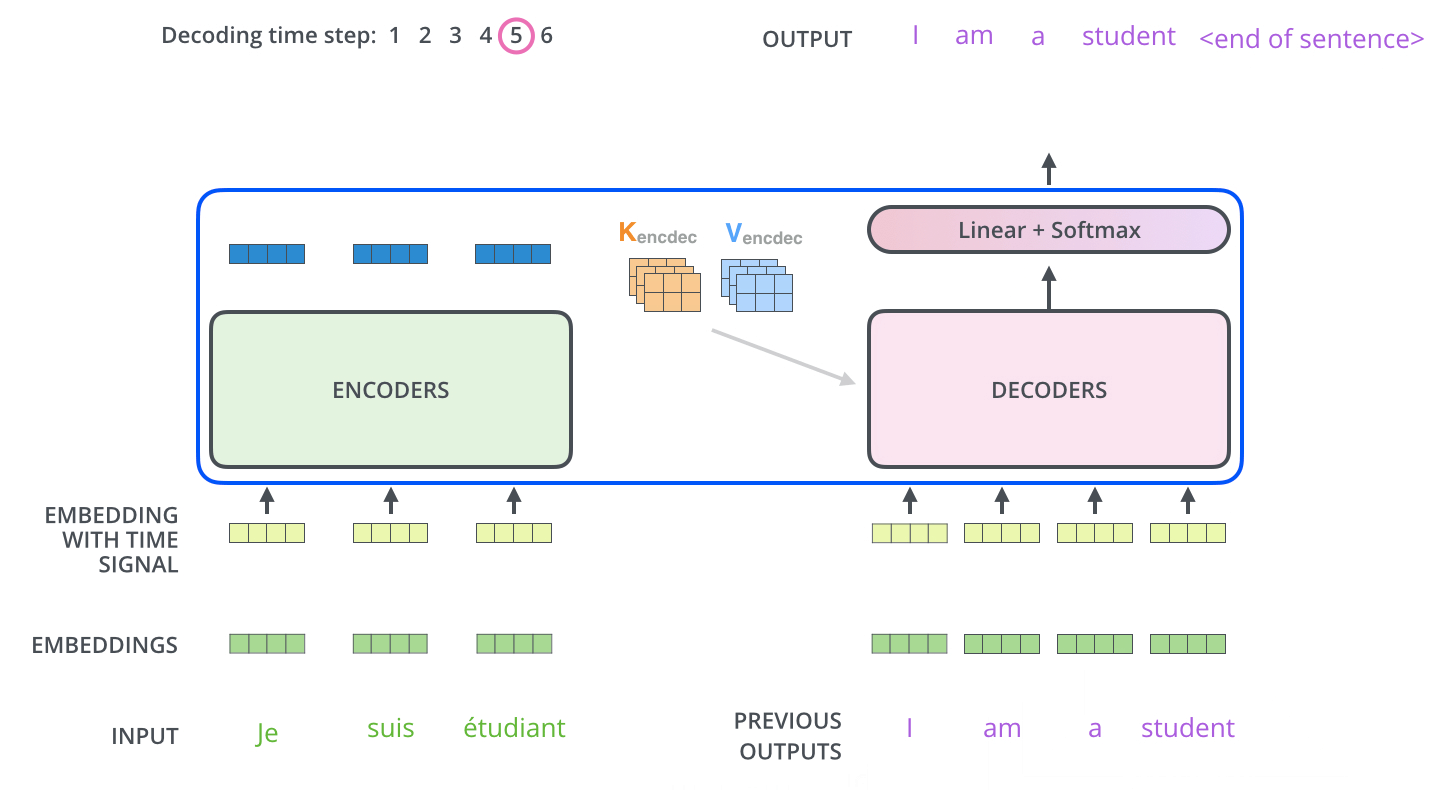
학습할 때 결국 입력과 정답을 알고 있는 상태이다. i번째 단어를 만드는 게 목적인데 모든 단어를 알고 있으면 학습에 의미가 없으니, 학습 단계에서 masking을 한다. 이전 단어들에만 dependent하고 뒤에 있는 단어들에 대해서는 dependent하지 않게 해 미래의 정보를 활용하지 않게 하는 방법이다. "Encoder-Decoder Attention"은 지금 decoder에 들어간 단어들, 이전까지 만들어진(generation) 단어들로만 query를 만들고 key, value는 encoder, 내가 주어진 input raw sequence에서 나오는 encoded vector를 활용하게 된다. 그 벡터를 어떻게 활용하는지는 MHA를 그대로 활용한다.
"Encoder-Decoder Attention" 레이어는 MHA처럼 작동하나, Q 행렬을 그 아래 레이어에서 가져온다는 점과 K와 V를 encoder stack의 output에서 가져온다는 점에서 다르다.

마침내, 단어들의 분포를 만들어서 그 중에 단어 하나를 매번 샘플링 하는 방식으로 돌아가게 된다. Softmax 레이어라는 선형 레이어를 통과하게 되는데, 선형 레이어는 단순히 FNN이다. 모델이 학습한 단어들 중에서 특정 단어의 score를 대응시켜서 선형 레이어를 통해 결과를 출력한다. softmax 레이어는 score를 확률(총합 1)로 바꿔 가장 높은 확률값을 가진 셀에 있는 단어로 바뀐다.
Transformer, now
NMT(기계 번역)에만 활용됐는데 최근 들어 transformer, self-attention이라는 구조를 단순히 단어들의 시퀀스를 바꾸는 것뿐만 아니라 이미지 도메인에도 활용하고 있다. Vision Transformer라는 논문은 이미지 분류할 때 encoder만 활용히여 encoder에서 나오는 첫 번째 encoded vector를 classfier에 집어넣는 방식이다. 차이점이 있다면 원래 NMT에서는 문장을 입력하는건 곧 단어들의 시퀀스가 주어지는 거지만 이미지의 경우 특정 영역으로 나누고 각각 영역에 있는 sub patch들을 linear layer를 통과해서 마치 하나의 입력인 것처럼 넣어준다. 물론 positional embedding이 들어가야 한다. attention 구조 자체는 입력값의 순서에 상관없이 출력이 불변하기 때문이다. 단순히 NMT나 NLP 영역에만 제공되는 게 아닌 vision 영역에도 활용되고 있다. DALL-E의 경우도 transformer의 decoder만 활용하여 문장에 맞는 이미지를 찾아준다.
http://jalammar.github.io/illustrated-transformer/
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Arabic, Chinese (Simplified) 1, Chinese (Simplified) 2, French 1, French 2, Japanese, Korean, Russian, Spanish, Vietnamese Watch: MIT’s Deep
jalammar.github.io
'AI / DL > boostcourse' 카테고리의 다른 글
| [딥러닝 기초 다지기] 5. Generative Models (2) (0) | 2022.12.13 |
|---|---|
| [딥러닝 기초 다지기] 5. Generative Models (1) (0) | 2022.12.02 |
| [딥러닝 기초 다지기] 3-3. Computer Vision Applications (0) | 2022.10.25 |
| [딥러닝 기초 다지기] 3-2. Modern CNN - 1x1 convolution의 중요성 (0) | 2022.10.24 |
| [Github으로 따라하는 버전 관리] Git 협업 (0) | 2022.10.07 |



댓글