Semantic Segmentation
어떤 이미지에 대해 픽셀마다 어디에 속하는지 분류하는 문제다. 예를 들어 자율 주행에서 내 앞에 있는 물체가 사람인지, 도로인지, 인도인지, 신호등인지 등에 대해 구분해야 하는 경우가 있다. 특히 센서를 활용하지 않고 이미지만을 갖고 다루는 문제에서는 Semantic Segmentation이 중요하다.
Fully Convolutional Network

Convolutional Feature Map을 원하는 차원 벡터로 가는 fully-connected layer로 만드는 흔한 CNN 과정이다.

Fully Convolutional Network는 dense layer를 없애서 output을 Conv layer으로 바꾼다. 이 dense layer 없애는 과정을 Convolutionalization라고 부른다. 이 경우나 일반적인 CNN이나 input과 output은 똑같이 나타난다. 파라미터까지 정확하게 일치하는 것이다. 그저 flatten하고 reshape하는 과정을 conv 하나로 바꿨기 때문이다.

FCN의 가장 큰 특징은 input dimension에 독립적(indenpendent)이다. 28 * 28 혹은 32 * 32로 만들어진 네트워크가 있을 때 그것의 output이 1 * 1 혹은 하나의 classification library 였다면, 더 큰 이미지에 대해서도 원래 네트워크는 할 수 없었지만(Reshape이 있었기 때문) 이 FCN은 input 이미지에 상관없이 네트워크가 돌아간다. 아웃풋이 커지게 되면 우리가 그거에 비례해서 뒷단의 special dimension network가 커지게 된다. Convolution이 가지는 Shared parameter의 성질 때문이다. Convolution은 input 이미지가 커지던 작아지던 상관 없이 동일한 Convolution filter가 동일하게 찍기 때문에 그게 찍어져서 나오는 resulting special dimension만 같이 커지지 여전히 동작시킬 수 있는 것이다. 그 동작이 마치 히트맵과 같은 효과가 있다. 해당 이미지에 특징이 어디에 있는지의 히트맵이 나타난다.

FCN은 어떠한 input 사이즈(스페셜 디멘젼)에도 돌아갈 수 있지만, 아웃풋 디멘션은 줄어든다. 그래서 coarse(드문드문 나타나는) output을 원래의 dense pixel로 늘려주는 과정을 통해 바꿔줘야 한다.

Deconvolution (Conv transpose)
Convolution의 역연산과 같다. special dimension 키워주며 늘리는 것이다. 사실 엄밀하게 얘기해서 Conv의 역연산은 존재할 수 없다. 복원하는 방법은 여러 경우가 있기 때문이다. 하지만 간단하게 역연산이라 생각하면 네트워크 architecture를 만들 때 파라미터 숫자와 네트워크 architecture의 크기를 계산하는 과정에서 계산하기 편해진다.

Detection
어느 물체가 어디에 있는지 찾는 것을 의미한다. 다만 픽셀 단위(per pixel)가 아니라 bounding box를 찾는 문제로 바뀐 것이다. 아래부터는 여러 Object Detection을 위한 여러 CNN의 종류를 다룬다.
R-CNN

이미지 안에서 Selective Search를 통해 2,000개의 Region을 뽑는다. 각 Region의 크기가 다를거고 무작위로 뽑는 것이다. CNN에 넣기 위해 각 feature를 똑같은 크기로 맞춘다. 그리고 AlexNet으로 feature를 계산하고 linear SVM으로 분류한다. R-CNN의 문제는 모든 Bounding Box를 CNN에 다 통과시켜야 한다는 단점이 있다.
SPPNet

R-CNN의 단점을 극복하기 위해 이미지 안에서 CNN을 한 번만 돌린다. 이미지 안에서 Bounding Box를 뽑고(Crop/Warp) 이미지 전체에 대해서 Conv Feature Map을 만든 다음 뽑힌 Bounding Box 위치에 해당하는 Feature Map의 tensor만 뜯어온다. 뜯어온 피처맵을 Spatial Pyramid Pooling을 적용하여 하나의 벡터로 바꿔준다. SPP은 Conv layer를 거친 피쳐맵을 입력으로 받고, 입력 이미지의 크기와 상관 없이 미리 설정한 bin(피라미드의 한 칸)의 개수와 CNN 채널 값으로 SPP의 출력이 결정된다. 그래도 텐서 여러 개 뜯어와서 하나의 벡터로 변환, 분류하는 과정도 오래 걸런다는 단점이 있다.
Fast R-CNN

- Bounding Box를 뽑는다. (Takes an input and a set of bounding boxes.)
- Feature Map을 한 번 얻는다. (Generated convolutional feature map)
- For each region, get a fixed length feature from ROI pooling.
- Two outputs : class and bounding-box regressor.
마지막에 NN를 통해서 Bounding Box를 어떻게 움직이면 좋을지 계산하고 label을 찾는다. SPP와 비슷한 과정이다. 뒷단에 NN과 ROI feature vector를 통해 회귀 / 분류를 진행한다.
Faster R-CNN
이미지에서 Bounding Box를 뽑아내는 Region Proposal도 학습하게 되었다. Bounding Box를 뽑아내는 Selective Search는 현재 풀고 싶어하는 Detection에 맞지 않을 수도 있었다. 그저 임의의 방법에 잘 동작하는 어떤 바운딩 박스를 뽑는 알고리즘이기 때문이다. Faster R-CNN은 Bounding Box candidate를 뽑는 것도 네트워크로 학습하고 이 네트워크를 Region Proposal Network(RPN)이라 부른다.
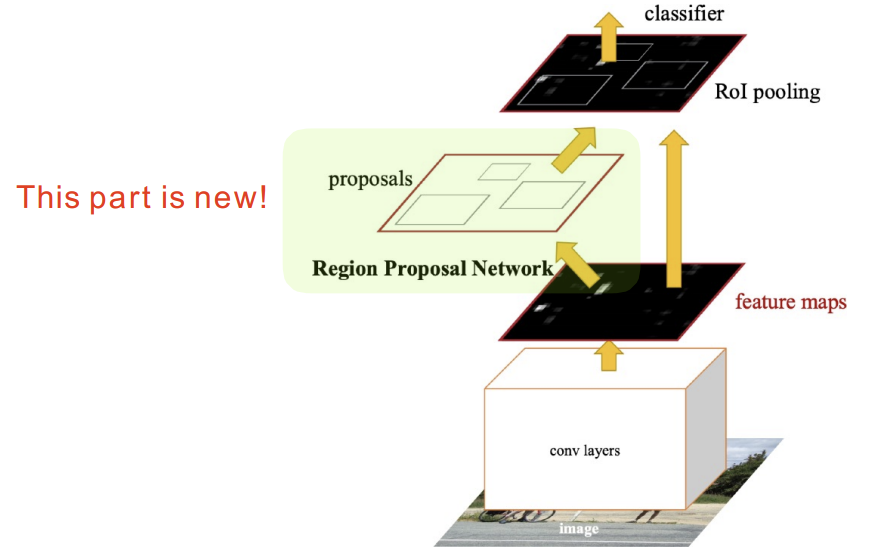
궁극적으로 RPN은 이미지가 있으면 특정 영역(패치)이 Bounding Box로서 의미가 있는지, 물체가 있는 지 없는 지를 찾아준다. 이 물체가 무엇인지 분류는 뒷단의 네트워크가 해준다.

Anchor box는 미리 Bounding Box의 크기를 정해놓은 것이다. 어떤 크기의 물체들이 있을 걸 알고 있는 것이다. 그리고 k개의 template을 만들어 이 템플릿이 얼마나 바뀔지 offset(변위차)을 찾고 궁극적으로 이 템플릿을 고정해놓는게 목표다. Fully conv가 모든 영역을 돌아가면서 찍는데 해당 영역에 물체가 들어있을지를 이 Fully conv가 들고 있게 된다.

Conv 피쳐맵은 9*(4+2)의 크기를 갖는다. 이 때 4는 Width, Height, offset(x, y)로 총 4개의 파라미터를 의미하고, 박스가 쓸모 있는지 분류하는 경우로 2(use it or not)다. 모든 Bounding Box가 쓸모 있다고 하면 CNN을 시행하는 이유가 없으니 상대적으로 적은 숫자의 bonding box proposal만 만들어져야 한다. Region이 어떤 클래스에 속하는지는 뒷단의 레이어에서 맞춘다.
YOLO(v1)
훨씬 빠른데(extremely fast object detection algorithm) 이미지 한 장에서 바로 찍어서 output이 나올 수 있기 때문이다. 정확히는 RPN과 분류 과정이 동시에 일어난다(It simultaneously predicts multiple bounding boxes and class probabilites).

이미지가 들어오면 S × S grid로 나눈다. 이미지에서 찾고 싶은 물체의 중앙이 해당 그리드 셀 안에 들어가면, 그 그리드 셀이 해당 물체에 대한 박스와 무엇인지를 같이 예측한다(If the center of an object falls into the grid cell, that grid cell is responsible for detection). 각각의 셀은 B개의 Bounding Box를 예측하게 된다. 이는 (x, y, w, h)로 나타내고 해당 박스의 신뢰도를 나타내는 Confidence를 계산한다. 동시에 그리드 중점에 있는 물체가 어떤 클래스인지 예측하게 된다. 박스를 찾고 그것을 따로 네트워크에 넣어 클래스를 찾았다면 YOLO는 동시에 돌아가는 과정이다.
https://yeomko.tistory.com/13?category=888201
갈아먹는 Object Detection [1] R-CNN
들어가며 2020년을 맞이하여 가장 먼저 Object Detection을 공부해보기로 결심하여, 논문들을 차례로 리뷰해보려 합니다. (열정 충만!) 그 첫 번째 논문으로 딥 러닝 기반의 Object Detection의 시작을 연 R-
yeomko.tistory.com
깔끔하게 정리해준 블로그를 찾았다.
'AI / DL > boostcourse' 카테고리의 다른 글
| [딥러닝 기초 다지기] 5. Generative Models (1) (0) | 2022.12.02 |
|---|---|
| [딥러닝 기초 다지기] 4-2. Sequential Models - Transformer (0) | 2022.11.02 |
| [딥러닝 기초 다지기] 3-2. Modern CNN - 1x1 convolution의 중요성 (0) | 2022.10.24 |
| [Github으로 따라하는 버전 관리] Git 협업 (0) | 2022.10.07 |
| [Github으로 따라하는 버전 관리] Git 기초 (0) | 2022.10.07 |




댓글